-
[DB] 커버링 인덱스, 실행 계획 Using indexBackend/개발 2023. 9. 11. 01:25반응형
작년에 작성했던 인덱스로 조회 시 개선되는 성능 확인해 보기 에 이어서, 이번에는 실행계획을 확인하고, 커버링 인덱스가 사용되는 쿼리는 어떤 것인지 좀 더 정리해보려고 한다.
기본 개념 및 특징
예전에 정리했던 인덱스 개념
https://github.com/kang-jisu/dev-study-log/blob/main/background/database/%EC%9D%B8%EB%8D%B1%EC%8A%A4.md인덱스
insert, update, delete (Command)의 성능을 희생하고 select(Query)의 성능을 향상시킨다.
데이터 파일이 있는 디스크에 직접 접근하지 않고, 메모리 저장소 내(인덱스) 안에서 최대한 해결하면서 성능을 개선할 수 있다.
클러스터드 인덱스
- 물리적으로 데이터가 정렬되어 있다.
- insert시에 인덱스의 행을 기준으로 정렬한다.
- 테이블당 하나의 클러스터드 인덱스를 포함한다.
- 설정 방법 ) PK로 설정하거나, clustered index로 추가하기
논 클러스터드 인덱스- 논리적으로 정렬되지 않은 상태로 저장
- 데이터를 직접 가지고 있지 않고 위치를 가리킨다. (클러스터드 인덱스를 가리키거나, 실제 데이터 저장 위치를 가리킴)
- 클러스터드 인덱스(정렬된 인덱스)에 의해 저장된다. 클러스터드 인덱스에 비해 검색속도는 느리지만 입력, 수정, 삭제에는 성능이 더 좋을 수 있다.
- 설정 방법 ) nonclustered index 추가, 혹은 기본 인덱스 설정
커버링 인덱스
- 실제 데이터의 접근 없이 원하는 데이터를 인덱스에서만 추출할 수 있는 인덱스
- 디스크 I/O를 통해 데이터 블록을 읽지 않고도 원하는 데이터를 가져올 수 있어 성능을 올릴 수 있다. (클러스터드 인덱스를 사용한다)
결국 커버링 인덱스들 이용해서만 조회가 가능하다면 성능을 개선할 수 있을 것이다! 지금 내가 작성하는 쿼리가 커버링 인덱스를 사용할 수 있는지를 확인하는 방법 중 하나가 실행 계획을 이용하는 것이다.
실행 계획
- https://dev.mysql.com/doc/refman/8.0/en/using-explain.html
작성한 쿼리에 대해서 explain 키워드를 사용하면 쿼리의 실행 계획을 확인할 수 있다.
간단히 말하면 이 작성된 SQL을 DB에서 어떻게 처리하여 가져올 것인지 예상하는 것인데, 몇 개의 / 어떤 종류의 쿼리가 있는지, 데이터를 인덱스로 조회하는지, 풀 스캔으로 조회하는지 등등 확인하면서 실제로 쿼리를 사용해 보기 전에 예측해 보며 쿼리를 최적화할 수 있다.
실행 계획의 결과로 여러 필드들이 있는데, 그중 Extra 필드를 보면 인덱스가 활용되고 있는지를 확인할 수 있다. (extra필드에 using index)
Extra
- Using where
- Range 검색 이후에는 직접 데이터 필드에 접근하여 추출하였음
- Using index
- 인덱스만으로 원하는 데이터를 추출하였음
- Using index condition
- 인덱스의 칼럼만 사용하여 조건의 일부를 평가할 수 있는 경우
- mysql 5.6 이상부터 인덱스 조건을 스토리지 엔진에 넘겨서 최대한 필터링
- 5.6 미만에서는 조회조건에 포함되는 필드가 모두 index여야만 가능했는데, 일부만 들어가도 필터링이 된다.
출처
- 인덱스 정리 및 팁 https://jojoldu.tistory.com/243
- Database index, 제대로 알아보기 https://gngsn.tistory.com/88
- Covering index, 성능 테스트 https://gngsn.tistory.com/194
- MySQL에서 커버링 인덱스로 쿼리 성능을 높여보자!! https://gywn.net/2012/04/mysql-covering-index/
- 커버링 인덱스 https://icarus8050.tistory.com/44
예제
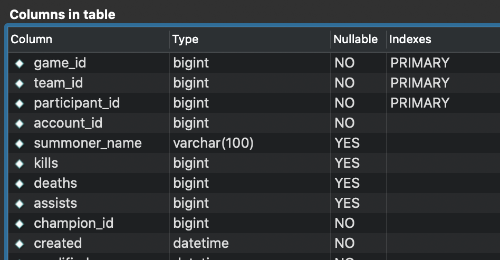

게임 참가자 테이블에서, 특정 챔피언별로 각각 최근 5건의 게임기록을 조회하려는 쿼리를 짜보려고 한다. ( 예제로 만들어볼 만한 적당한 요구사항이 없어서 대충 지어내보았다., )

아무런 설정을 안 한 상태에서는 PK인 (game_id, team_id, participant_id)만 index로 설정이 되어있다.
특정 챔피언, 시간 순 정렬 조회를 하기 위해서는 champion_id와 created로 where절에 서브쿼리를 넣어 작성해야 한다.
SELECT * FROM game_record_participants as ori WHERE ( SELECT count(*) FROM game_record_participants as sub WHERE sub.champion_id = ori.champion_id and sub.game_id <= ori.game_id ) <= 5 ;1) 서브쿼리에 인덱스 없이 조회

explain으로 실행계획을 조회하면 id=2인 쿼리의 Extra가 Using where이다. rows를 똑같이 11850(전체 rows 수)만큼 조회하고 있는 것이다.

그래서 실제로 쿼리를 수행히보면 10000개의 rows에서 770개의 rows를 가져오기 위해서 90 sec나 걸린 것을 볼 수 있다. ㄷ_ㄷ
2) 서브쿼리에 사용되는 칼럼을 인덱스로 만들어서 조회
CREATE INDEX ix_query ON game_record_participants (champion_id,created);
사용되는 칼럼인 champion_id와 created를 인덱스로 만들어줬다.


똑같이 쿼리를 실행했더니 0.5 sec 만에 실행이 되었고 Extra에 Using index가 쓰였으며 rows도 75개만 가지고 왔다. 생각보다 큰 성능 차이가 있는 것 같다.
DB를 조회하는 쿼리를 작성할 때 그냥 단순히 동작만 하도록 쿼리를 짜곤 했는데, 작성한 쿼리에 대해서 실행계획으로 확인해 보고 만들어 있는 PK나 인덱스를 활용해 쿼리가 작성되고 있는지 확인한다면 조금 더 성능을 고려해서 만들 수 있을 것 같다.
아직 너무 모르는 게 많아서 mysql에 대해서 좀 더 공부해서 개념을 보완해야겠다. T_T
'Backend > 개발' 카테고리의 다른 글
[Spring Boot] @Transactional Rollback 관련 트러블슈팅 (0) 2023.01.30 [Spring Boot] List의 null값 처리하기2 - 일급컬렉션, @RequestBody (0) 2022.05.15 [Spring Boot] 카카오 로그인 - 1 (0) 2022.05.01 [Spring Boot] JPA Flush 특징, 문제 해결 (0) 2022.04.17 [Spring Boot] List의 null 값 처리하기1 - CustomConverter로 @RequestParam (0) 2022.04.07